
In this post we are going to scrape an ecommerce website. We’ll get into each individual product page and retrieve our information from there. This is the website we are going to scrape – it’s an online shop that sells whisky.
Do remember to check out the robots.txt file before scraping any website. You have to keep in mind that you can unnecessarily bring a website down and can harm their services. So, please do not flood their servers with scraping requests.

I have gone to a subsection of the site here, and it looks like a there are quite a lot of choices. And if you want to find out what the user ratings are for every product, then you have to open each and every product page to get the ratings (you can’t find them on the main page).

So we’re going to get a list of all the links for every single product from all five pages. Then we are going to go into each product individually and scrape our desired data.
But some of them don’t have a rating. Instead, in those cases, we’ll go into each product and get the about text as well. Let’s go!
How to Setup the Scraping Project
Our setup is pretty simple. Just create a folder and install Beautiful Soup, pandas, and requests. To create a folder and install the libraries, enter the commands given below. I am assuming that you have already installed Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
pip install pandasNow, create a file inside that folder and name it anything you like. I am using the name scraper.py. We are going to import requests, pandas, and bs4.
import requests
from bs4 import BeautifulSoup
import pandas as pdNow, we are going to set the base URL of the main page because we’ll need that when we construct our URLs for each of the individual products.
Also, we will send a user-agent on every HTTP request, because if you make GET request using requests then by default the user-agent is Python which might get blocked.
So, to override that, we will declare a variable which will store our user-agent.
baseurl = "https://www.thewhiskyexchange.com"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'}Now we need to investigate the page so that we can figure out where the links are and how we’re going to get them. You have to open Chrome dev tools by using inspect (Command+Option+C).

We will write a script to go through each one of these and create a URL for us. To do that we need to make an HTTP call first. Then we will extract the li element using BeautifulSoup.
k = requests.get('https://www.thewhiskyexchange.com/c/35/japanese-whisky').text
soup=BeautifulSoup(k,'html.parser')
productlist = soup.find_all("li",{"class":"product-grid__item"})
print(productlist)Just to check that we are on the right track, we have printed the complete list.
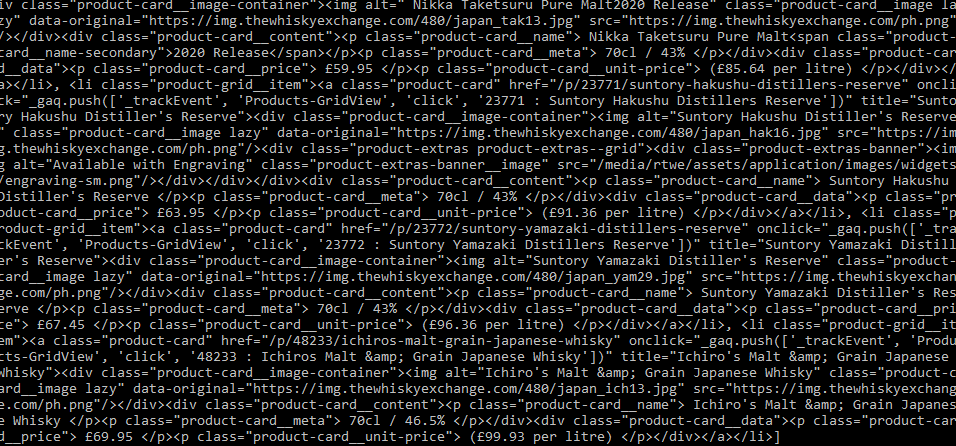
Next, get the HTML for the items on this page. Now, inside each of these lists there is a link to the individual product page. We will write a script to scrape all those links from the productlist.
productlinks = []
for product in productlist:
link = product.find("a",{"class":"product-card"}).get('href') productlinks.append(baseurl + link)Here first we have declared an empty list called productlinks. Then we have used a for loop to reach each productlist element to extract the link. We have used the .get() function to get the value of the href attribute. After extracting the link we store every link inside the list productlinks. Since we have to create a legit URL, we have added baseurl to the link.

As we discussed earlier, we have to cover all five pages of the website. To do so we will introduce a for loop before making the HTTP call. Since there are 5 pages we will run the loop from 1 to 6. Also, make sure to change the target URL.
productlinks = []
for x in range(1,6):
k = requests.get('https://www.thewhiskyexchange.com/c/35/japanese-whisky?pg={}&psize=24&sort=pasc'.format(x)).text
soup=BeautifulSoup(k,'html.parser')
productlist = soup.find_all("li",{"class":"product-grid__item"})
for product in productlist:
link = product.find("a",{"class":"product-card"}).get('href')
productlinks.append(baseurl + link)This will give us all the links available on the website. Now to confirm, you can print the length of productlinks. We should get 97 links in total.
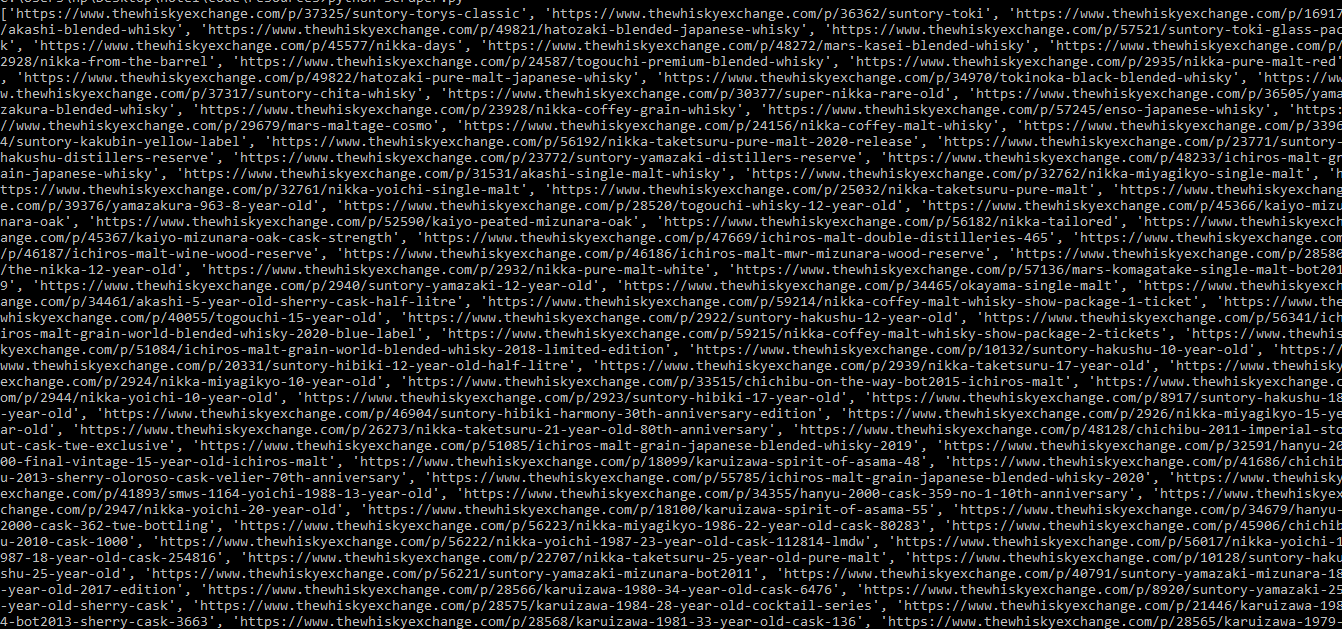
Now we can loop through each of these links to extract the product information from each page and then store it in another list or dictionary.
Next we are going to analyze the pattern in which the information is displayed on the product page. We will extract the name, price, ratings, and about text.

The Name is under an h1 tag, the about text is under the div tag, price is under a p tag, and rating is under the span tag. Now, let’s extract them.
data=[]
for link in productlinks:
f = requests.get(link,headers=headers).text
hun=BeautifulSoup(f,'html.parser')
try:
price=hun.find("p",{"class":"product-action__price"}).text.replace('\n',"")
except:
price = None
try:
about=hun.find("div",{"class":"product-main__description"}).text.replace('\n',"")
except:
about=None
try:
rating = hun.find("div",{"class":"review-overview"}).text.replace('\n',"")
except:
rating=None
try:
name=hun.find("h1",{"class":"product-main__name"}).text.replace('\n',"")
except:
name=None
whisky = {"name":name,"price":price,"rating":rating,"about":about}
data.append(whisky)Here, things are pretty straightforward. We have started a for loop to iterate over every individual link of productlinks. We will make an HTTP GET call to every link and then extract the price, name, rating and about text.
We are using try and except to avoid any errors if any element is not found. Use the replace function to remove all the line breaks or unnecessary strings we get along with the extracted information.
We have created a dictionary with the name whisky where we will store all the extracted information. At the very end we are storing the dictionary inside the list data.
Now before printing the data we are going to make the data more presentable. Here we will use pandas. I love using pandas!
df = pd.DataFrame(data)
print(df)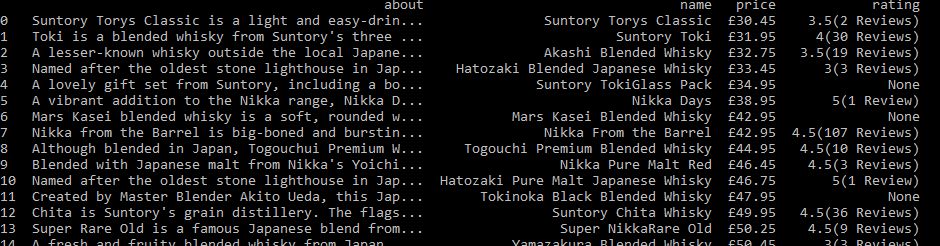
Here’s the Complete Code for the Scraper
import requests
from bs4 import BeautifulSoup
import pandas as pd
baseurl = "https://www.thewhiskyexchange.com"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'}
productlinks = []
t={}
data=[]
c=0
for x in range(1,6):
k = requests.get('https://www.thewhiskyexchange.com/c/35/japanese-whisky?pg={}&psize=24&sort=pasc'.format(x)).text
soup=BeautifulSoup(k,'html.parser')
productlist = soup.find_all("li",{"class":"product-grid__item"})
for product in productlist:
link = product.find("a",{"class":"product-card"}).get('href')
productlinks.append(baseurl + link)
for link in productlinks:
f = requests.get(link,headers=headers).text
hun=BeautifulSoup(f,'html.parser')
try:
price=hun.find("p",{"class":"product-action__price"}).text.replace('\n',"")
except:
price = None
try:
about=hun.find("div",{"class":"product-main__description"}).text.replace('\n',"")
except:
about=None
try:
rating = hun.find("div",{"class":"review-overview"}).text.replace('\n',"")
except:
rating=None
try:
name=hun.find("h1",{"class":"product-main__name"}).text.replace('\n',"")
except:
name=None
whisky = {"name":name,"price":price,"rating":rating,"about":about}
data.append(whisky)
c=c+1
print("completed",c)
df = pd.DataFrame(data)
print(df)
Conclusion
Finally we have managed to scrape all the information from every page of the website. Similarly you can scrape other text from this website. As an exercise you can try scraping this website. If you have any questions for me, please dm me on my twitter handle.
Source: Web Scraping in Python – How to Scrape an eCommerce Website Using Beautiful Soup and Pandas