如何在scrapy中集成selenium爬取网页
最新推荐文章于 2024-12-31 04:49:15 发布
Kosmoo
最新推荐文章于 2024-12-31 04:49:15 发布
阅读量2.4w
收藏 130
点赞数 24
分类专栏:
python爬虫
文章标签:
scrapy爬虫
scrapy selenium
scrapy集成selenium
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/zwq912318834/article/details/79773870
版权
本文详细介绍了如何在Scrapy中集成Selenium,以应对JavaScript渲染的复杂网页。通过分析Scrapy请求流程,作者展示了在下载中间件中使用Selenium的实现方式,并针对Spider关闭时Chrome未退出及多Spider并发问题提出了改进方案。
摘要由CSDN通过智能技术生成
如何在scrapy中集成selenium爬取网页
1.背景
我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium。requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化)。
在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦。 尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心
1.背景
我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium。requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化)。
在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦。 尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面后台发生了怎样的请求,也不需要分析整个页面的渲染过程,我们只需要关心页面最终结果即可,可见即可爬,但是selenium的效率又太低。
所以,如果可以在scrapy中,集成selenium,让selenium负责复杂页面的爬取,那么这样的爬虫就无敌了,可以爬取任何网站了。
2. 环境
python 3.6.1
系统:win7
IDE:pycharm
安装过chrome浏览器
配置好chromedriver(设置好环境变量)
selenium 3.7.0
scrapy 1.4.0
3.原理分析
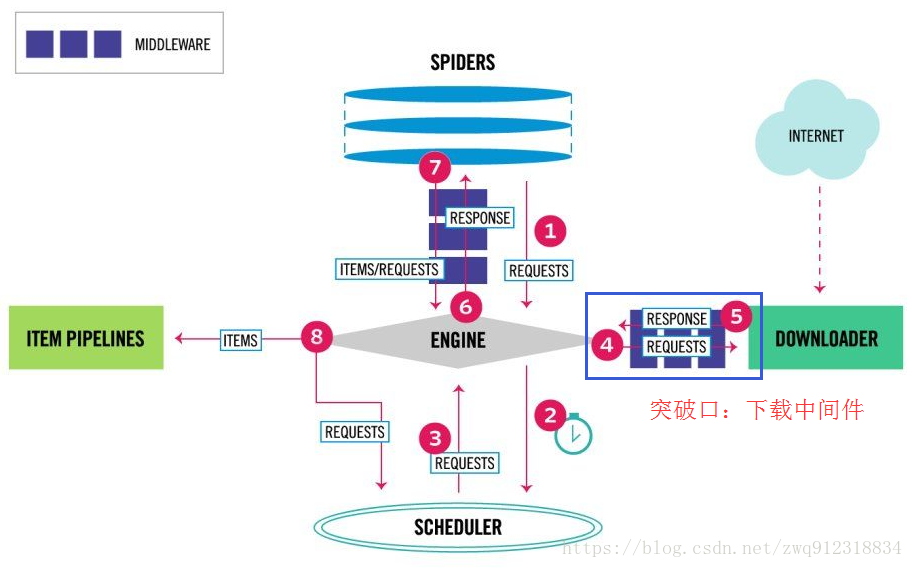
3.1. 分析request请求的流程
首先看一下scrapy最新的架构图(https://blog.csdn.net/zwq912318834/article/details/79720742):
————————————————
部分流程:
第一:爬虫引擎生成requests请求,送往scheduler调度模块,进入等待队列,等待调度。
第二:scheduler模块开始调度这些requests,出队,发往爬虫引擎。
第三:爬虫引擎将这些requests送到下载中间件(多个,例如加header,代理,自定义等等)进行处理。
第四:处理完之后,送往Downloader模块进行下载。
从这个处理过程来看,突破口就在下载中间件部分,用selenium直接处理掉request请求。
————————————————
版权声明:本文为CSDN博主「Kosmoo」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zwq912318834/article/details/79773870
Source: (45条消息) 如何在scrapy中集成selenium爬取网页_Kosmoo的博客-CSDN博客_scrapy selenium