
PgAdmin for PostgreSQL Database
The content provided appears to be a structured outline or navigation menu for the pgAdmin website, a popular open-source administration and development platform for PostgreSQL. The structure is repetitive, likely…
RFID, Software Development and Physical Security
The content provided appears to be a structured outline or navigation menu for the pgAdmin website, a popular open-source administration and development platform for PostgreSQL. The structure is repetitive, likely…
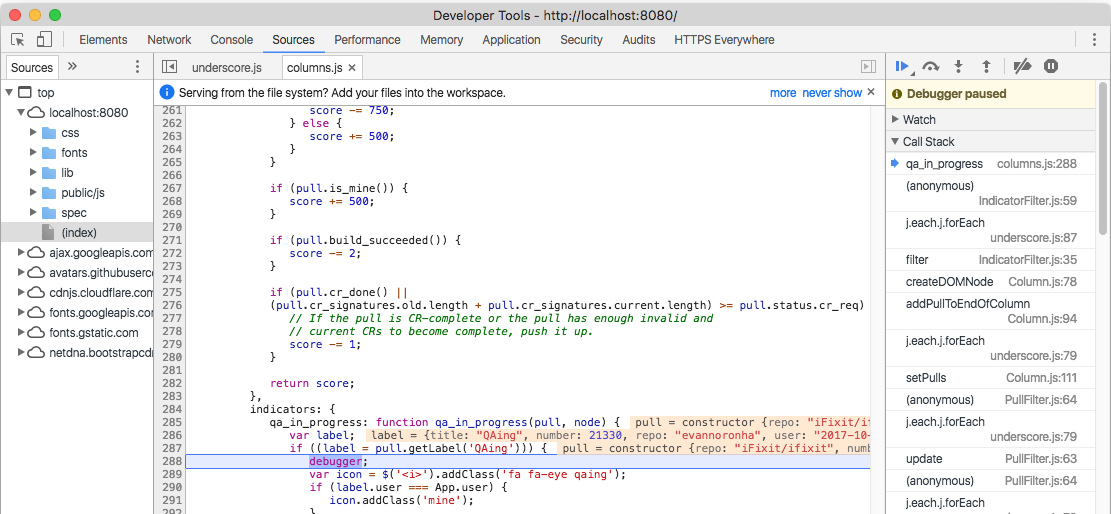
你的Py教練Mike 搜尋 搜尋此網誌 快速搞懂Python網頁爬蟲爬取AJAX動態網頁的秘訣 10月 04, 2020 Photo by LinkedIn Sales Navigator on Unsplash 在使用Python網頁爬蟲爬取網頁時,有些網頁為了提升使用體驗及維持執行效能,會使用AJAX的技術, 非同步向伺服器傳送參數,取得資料來進行顯示, 使用者不會感受到畫面有任何的閃爍或停頓,依然能夠正常的使用網頁。 不過想要爬取這種類型的網頁,點擊滑鼠右鍵檢視原始碼時,會看到滿滿的Unicode編碼資料,沒有HTML標籤,這時候要來爬取網頁時,會完全抓不到資料。 由於筆者在爬取 KKday網站 的一日遊票券時,就是遇到這樣的情況,所以想藉此來和大家分享Python網頁爬蟲該如何爬取AJAX類型的網頁,其中的開發流程如下: 分析網頁 分析AJAX回傳結果 開發Python網頁爬蟲 一、分析網頁 首先,前往 KKday網站 ,假設在搜尋的地方輸入「新竹市」進行搜尋後,在網頁左側的「所有商品類別」中,選擇「觀光旅行」下的「一日遊」,就可以查到新竹市一日遊的相關票券,如下圖: 這時候,點擊滑鼠右鍵檢視網頁原始碼時,會完全找不到網頁上所顯示的票券名稱,都是Unicode編碼,這就是典型的 Source:…

相信大家都知道,取得資料後能夠進行許多的應用,像是未來的趨勢預測、機器學習或資料分析等,而有效率的取得資料則是這些應用的首要議題,網頁爬蟲則是其中的一個方法。 網頁爬蟲就是能夠取得網頁原始碼中的元素資料技術,但是,有一些網頁較為特別,像是社群平台,需先登入後才能進行資料的爬取,或是電商網站,無需登入,但是要透過滾動捲軸,才會動態載入更多的資料,而要爬取這樣類型的網頁爬蟲,就稱為動態網頁爬蟲。 該如何實作呢?本文將使用Python Selenium及BeautifulSoup套件來示範動態網頁爬蟲的開發過程,重點包含: BeautifualSoup vs Selenium 安裝Selenium及Webdriver 安裝BeautifulSoup Selenium get()方法 Selenium元素定位 Selenium send_keys()方法 Selenium execute_script方法 BeautifulSoup find_all()方法 BeautifulSoup getText()方法 一、BeautifualSoup vs Selenium BeautifulSoup套件相信對於開發網頁爬蟲的人員來說,應該都有聽過,能夠解析及取得HTML原始碼各個標籤的元素資料,擁有非常容易上手的方法(Method),但是,對於想要爬取動態網頁資料來說,則無法達成,因為BeautifulSoup套件並沒有模擬使用者操作網頁的方法(Method),像是輸入帳號密碼進行登入或滾動捲軸等,來讓網頁動態載入資料,進行爬取的動作。 所以,這時候,就可以使用被設計於自動化測試的Selenium套件,來模擬使用者的動作,進行登入後爬取資料或滾動卷軸,並且能夠執行JavaScript程式碼,這些就是Selenium與BeautifulSoup套件最大不同的地方。對於開發Python動態爬蟲來說,就可以結合Selenium套件以上的特點,讓網頁動態載入資料後,再利用BeautifulSoup套件簡潔的方法(Method),將所需的資料爬取下來。 本文就是利用這樣的概念,利用Selenium套件登入Facebook後,前往粉絲專頁,執行滾動卷軸的JavaScript程式碼,讓網頁動態載入資料後,再使用BeautifulSoup套件爬取貼文標題。 二、安裝Selenium及Webdriver 首先,利用以下指令安裝Python的Selenium套件: $ pip…
The content provided appears to be a structured guide or resource hub for learning Python, offering a variety of tools and materials to support learners at different stages. Below is…