如何在scrapy中集成selenium爬取网页
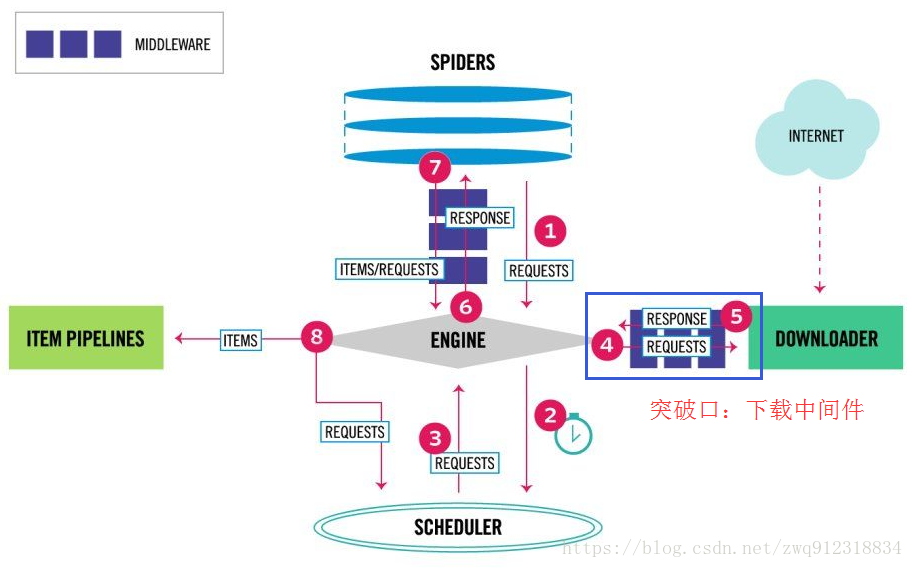
如何在scrapy中集成selenium爬取网页 最新推荐文章于 2024-12-31 04:49:15 发布 Kosmoo 最新推荐文章于 2024-12-31 04:49:15 发布 阅读量2.4w 收藏 130 点赞数 24 分类专栏: python爬虫 文章标签: scrapy爬虫 scrapy selenium scrapy集成selenium 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 本文链接:https://blog.csdn.net/zwq912318834/article/details/79773870 版权 本文详细介绍了如何在Scrapy中集成Selenium,以应对JavaScript渲染的复杂网页。通过分析Scrapy请求流程,作者展示了在下载中间件中使用Selenium的实现方式,并针对Spider关闭时Chrome未退出及多Spider并发问题提出了改进方案。…